Date: Summer 2020
Background
Fidelity is building a digital-asset tool for institutional investors and researchers. The team approached me for help prioritizing the features on the roadmap–both overall product features and specific dashboard features–and getting direction on pricing and packaging. Later on, they wanted to get evaluative feedback on a couple of iterations of the product design.
Process
Once the learning objectives were defined, I focused on defining the appropriate methods. For feature prioritization, I was experienced with best-worst scaling techniques and familiar with Kano analysis. Pricing and packaging testing methods, however, were new to me. I reached out to the UX Research Guild at Fidelity for help and was directed to market researchers who introduced me to Van Westendorp & Monadic price tests and provided some best practices. One pro-tip was that price testing with target users should happen very close to launch, when the product is fully formed. This was going to be early stage testing, so not ideal. But I felt optimistic we could at least get some direction.
Alas, these methods were quantitative. And fussing over quantitative methods is pointless if you can’t get appropriate sample sizes. Would my current recruit vendors be able to find hundreds of institutional crypto investors? Nope. This is a niche of a niche audience.
So before proposing a set of research methods to the product team, I directed my attention to recruiting. By following several breadcrumb trails, I found four specialty recruiters who could find 20-50 target users each. I had a favorite vendor–one we had worked with on many studies in the past–but they were the most expensive. I used a lower quote as leverage and negotiated my top choice down to parity. With this, the product team could afford about 50 paid participants, plus 10 (free!) Fidelity employees in relevant roles. Not ideal, but not too shabby either!
To make do with this small sample size, we combined the feature prioritization, pricing, and packaging learning objectives into a hybrid quant/qual study: 60-minute, 1:1 interviews with ~40 participants in which I would:
- Administer an online best-worst scaling survey to prioritize overall product features
- Moderate a Kano questionnaire to prioritize dashboard features
- Ask an open-ended pricing question, and
- Have participants group proposed features into “basic” and “premium” packages.
This was unlike any other study I have moderated. It was a heavy lift in terms of set-up/logistics, and the subject matter is challenging. I used Mural.ly boards to show the dashboard features and lead the participants through the Kano questionnaire (#2) and the packaging exercise (#4). I used most-least.io for the best-worst scaling (#1). And the product team–far more knowledgeable about the institutional digital-asset space than I–graciously IM’d me throughout the sessions when I got in over my head.

I used a Mural board to help facilitate Kano questions on the proposed dashboard features.
Toward the end of the second week of testing, the recruiter shared that they found some qualified candidates who had schedule conflicts. Because we were using quant methods, I simply adapted the interview into a survey in Qualtrics and most-least.io. The qualitative feedback from these Ps would be limited to a few open-ended questions, but the rest would remain in tact. Yay for pivoting!

Here are the Kano questions adapted to a survey. From my experience in the interviews, I knew that participants got confused on the dysfunctional answer options, so I made them a bit clearer for the unmoderated version.
Results
We ended up running 31 interview sessions and received 5 survey responses. For the quant-qual interviews, we had quant-qual findings. The data clean-up and synthesis were significant.
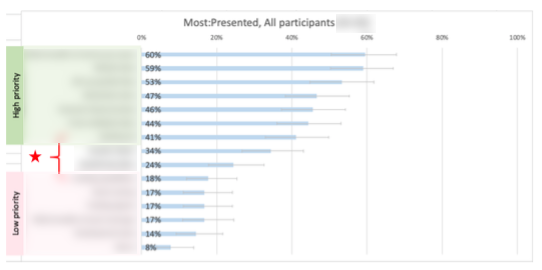
Overall product feature prioritization brought to you by most-least.io. Despite the small sample, we saw distinct trends here. One of the product features that was touted as a differentiator scored very low and has since been scrapped.

I did a continuous analysis of the Kano results. Naturally, the error bars are large due to small sample size. But I was very happy to see that the importance ratings aligned with the feature categorizations.
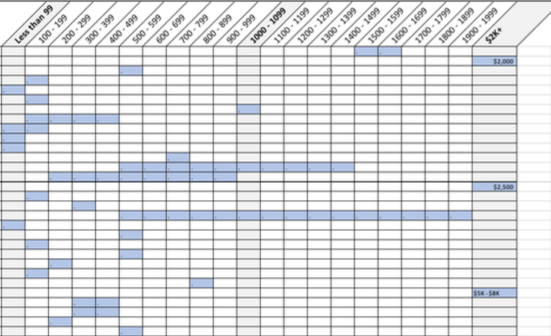
We asked participants about price in an open-ended question. Their ranges were all over the map, but because this was a (mostly) moderated study, we captured the mental models upon which they based their responses. That will be helpful when positioning the product. So… not definitive, but still valuable.
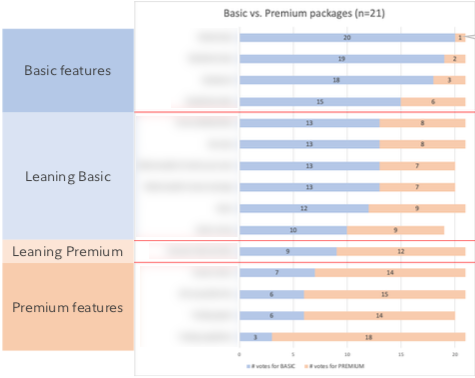
We had participants use Mural.ly to drag & drop features into “basic” and “premium” categories.
And finally, actual qualitative insights!
In addition to the report, a colleague and I compiled a video highlight reel that the product team could share in its steering committee presentation. It was a big hit, and obviously would not have been possible with a straight quant study.

Still from the 5-minute video highlight reel from the interviews. Steering committee ate this up!
Conclusion
While not the most technically rigorous way to test for feature prioritization and pricing, embracing a hybrid quant/qual method—and adding ample caveats about sample size to the reporting—enabled me to get directional feedback from a very small, niche, difficult-to-recruit target-user population. And I learned a ton about the needs and pain points of institutional digital-asset traders and researchers.
